Frequently Asked Questions
Accounts
How Do I Get an RDHPCS Account?
PW login is getting a “Invalid username or password” error.
If you are an on-premise HPC system user logging into Parallel Works for on-prem HPC systems access, and getting an: “Invalid username or password” error, follow these steps before requesting help:
Make sure you are using your RSA token to authenticate. CAC authentication is not supported.
Make sure you can successfully log into the on-prem HPCS system – Analysis, Ursa, Gaea, Hera, or Niagara.
Now try to login to the Parallel Works platform.
If you continue to get an “Invalid username error”, confirm your RDHPCS SSO authentication status.
As needed, request help.
My RSA Token is locked
Wait 15 minutes and try again.
As needed, request help for your accounts, with a subject line of “Please check RSA token status.” If you can, include the full terminal output you received when you tried to use your token.
I forgot my passphrase, how do I reset it?
On the 4th attempt the system will prompt to recreate a passphrase. See Connecting for the first time.
Jobs
My job hasn’t started and I have been waiting a long time. What is wrong?
We use the Slurm “FairShare” algorithm for scheduling jobs and jobs are scheduled based on job priority.
You can find the “current” FairShare value of your project(s) by running the
saccount_params
Please see the following link for details about how this algorithm works in our environment: Priority and Fairshare. More often that not, your job isn’t starting because the system is full.
The RDHPCS systems are for research and development and instantaneous job starts should not be expected. Even when it might appear that there are free resources, there are often reservations that are securing resources for future use.
One change you can make that will help the system schedule your job sooner is to specify an accurate wall clock time (‘’-l walltime=hh:mm:ss’’). You should pick a time that is roughly 10-15% longer than your average job length. By doing this, and not just putting a default time of 8:00 hours, the system can better optimize how resources are used and find space on the system to run your job sooner.
You can also run the following command to check for errors that are preventing the job from running:
scontrol show job jobid
where jobid is the job ID of the job in question.
My job hasn’t started and it is in a reservation, what is wrong?
If you have this problem, please run the following commands and send the output to the Help Desk so that we can diagnose the problem.
# squeue --job $JOB_ID
# scontrol show job $JOB_ID
What is the meaning of the exit code?
When you check a job status with the showq -c or checkjob command, it is good to know the meaning of the completion code, or the CCODE column for showq. Here is a list of exit code Moab reported from Torque:
0 /* job exec successful */
-1 /* job exec failed, before files, no retry */
-2 /* job exec failed, after files, no retry */
-3 /* job execution failed, do retry */
-4 /* job aborted on MOM initialization */
-5 /* job aborted on MOM init, checkpoint, no migrate */
-6 /* job aborted on MOM init, checkpoint, ok migrate */
-7 /* job restart failed */
-8 /* exec() of user command failed */
-9 /* could not create/open stdout stderr files */
-10 /* job exceeded a memory limit */
-11 /* job exceeded a walltime limit */
-12 /* job exceeded a cpu time lim
When the number for the exit code is more than 128, subtract 128 from the given exit code to see what signal was used to kill the job. For example 143 is another common exit code seen:
143 - 128 = 15
To see which signaled the response to what number you can use the command:
kill -l
Which lists the signals in order. And you will see that 15 is TERM (terminated).
So when a job has a completion code of 143, the job was terminated with signal 15 (which is the TERM signal), which suggests that the job was killed by the user or system administrator.
All my multi-node MPI jobs are timing out, even simple jobs! What is wrong?
If you find that all of your multi-node jobs are getting stuck and running into wall time limit exceeded error, it is possible that you have a problem with your keys, or some cases, because of incorrect permissions settings on the /.ssh directory.
A simple way to check if this is indeed the problem is to try the following:
While logged into the one of the front end nodes, try to ssh to another front end node. Normally you should be able to do this without being prompted for a password. If you are prompted for a password, refer to the next question.
My multi-node jobs fail on mpirun/mpiexec.
If you are able to run some parallel jobs across nodes but not others, especially if the failure is right after the mpirun (or ;mpiexec) command, the most likely cause of that failure is the stack size setting. You need to set the stack size to be the appropriate value for your application. If you’re not sure it could set it to "unlimited". There are some rare instances we have seen problems when set to "unlimited", but so far most of the time it has been fine. If you’re not able to determine a good number to set to you could try the unlimited setting.
How you set the stack size depends on what your login shell is, independent of the shell that is used for lunch and the job.
If your login shell is csh/tcsh:
Add the following line to your /.cshrc file:
limit stacksize unlimited
If your login shell is bash:
Add the following line to your /.bashrc file:
ulimit -S -s unlimited
Note
Capital-S for soft limit
Please also make sure that you have a .bash_profile file that has contains the following (in addition to whatever you have for your own environment):
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
Note
Trying to set the stack size within the job file does not work!’’’ This is because setting it within the job only changes the setting on the head node for the job, but the remaining nodes only get the default setting, or whatever is set in the initialization files.
User Issues
How do I change my default login shell?
To change your default shell:
Log into AIM.
Click “view your information in AIM”.
Navigate down to the “Projects and Account Information” section.
Click the dropdown menu (middle panel) next to “Shell selection”.
Choose your shell from the list and click the “Submit Changes” button in the bottom section
Once your help ticket is processed, the change should be complete within 24 hours.
How can I recover recently deleted files from /home?
The home filesystem is backed up regularly. However, the filesystem also supports snapshots, which will allow you to retrieve your own files if they have been deleted over the last few days.
Look at the snapshot directory (/home/.snapshot) to see what options are available. Each directory listed there represent a day. As an example on Hera:
2021-09-17_0015+0000.homeSnap 2021-09-20_0015+0000.homeSnap
2021-09-23_0015+0000.homeSnap
2021-09-18_0015+0000.homeSnap 2021-09-21_0015+0000.homeSnap
AUTO_SNAPSHOT_8820a150-8f27-11d5-95ff-040403080604_694
2021-09-19_0015+0000.homeSnap 2021-09-22_0015+0000.homeSnap
You can then access the old files in your copy of your home directory under the appropriate snapshot.
For example, if you want to recover Hera files in your <code>$HOME</code> from September 22nd, 2024, and your user name is Robin.Lee:
$ cd /home/.snapshot/2021-09-22_0015+0000.homeSnap/Robin.Lee
Copy the files you want from the here, the snapshot, to anywhere in your real home.
Why am I not able to ssh between nodes, it is asking me for a password!
If you are getting prompted for a password while trying to SSH between FE nodes there are two possible causes. The causes of those problems and their fixes are shown below (please note you may need to fix only one of these issues):
1. You may have generated new keys and not added them to the authorized_keys file. The fix is to run the following:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
You may have inadvertently changed permissions for your ~/.ssh directory. The fix is to run the following command:
chmod -R 700 ~/.ssh
Note
It is important to note that the keys generated should be created without a passphrase. That is, when you are generating the keys using ssh-keygen please be sure to press Enter when prompted for the passphrase for the key.
You should now be able to access the requested node via SSH without being prompted for a password.
How can I recover files that I accidentally deleted from my project space?
You usually cannot.
Please note that only the /home filesystem is backed up. Project space is typically assigned on very large high performance file systems and hence cannot be backed up. ‘’’Any files deleted from project space are gone forever and cannot be recovered.’’’
So it is important to have a second copy of files that are irreplaceable. Files like source files should typically stored in some source code repositories and irreplaceable data files should be stored in HPSS tape archive.
How do I find out which directories and partitions I can use?
Refer to the Slurm pages.
How do I find out what my project quota is?
Refer to the allocation pages.
Can you please install the xyz python package(s)?
There are way too many combinations in which users use python so, it is not practical to have a “common” python installation that is applicable for all users. Python works best when users install the packages they need in their own project space.
We have now opened up access to the conda forge repositories so it is no longer necessary to use the RDHPCS mirror for installing the Python packages you need. You should now be able to install Python packages the same way you would on your local desktop/laptop.
Please search for “conda” in the search field for specific instructions (if any) on how to maintain your own python installations in our environment.
Why are my jobs failing intermittently?
We are getting reports of jobs failing intermittently with a job timeout error.
At least in some instances this has been traced to an environment variable setting that is no longer valid. We were able to duplicate this problem very easily with a simple MPI Hello World program.
The setting in question is the following environment variable:
export I_MPI_FABRICS=shm:ofa
This setting should no longer be set. When this variable is set we were able to confirm that even a simple MPI Hello World code can fail intermittently even when run on the same set of nodes. While it is true that it happens only some nodes and rebooting them clears the nodes, not setting the above environment variable does not cause this problem. We do plan to reboot the nodes that reboot the problem, but users can take action to avoid running into this problem by simply unsetting the above environment variable.
If you are still seeing this error even though you have not set this environment variable please submit a help ticket to report the problem.
Why am I getting these errors? I am using hpc-stack for NCEPLIBS
If you are using hpc-stack please keep in mind that this is a software stack that is installed and maintained by the NCEPLIBS team. Please refer to the hpc-stack official supported distribution.
If you have problems, particularly with modules or NCEP libraries, it is very likely you are using an unsupported version of their libraries. If you are using the official version and still having problems, you should submit an “issue” ticket at the above link.
I am using spack-stack and getting some errors
The spack-stack software is installed and maintained by the EPIC team, and the RDHPCS administrators are not able to provide assistance with these issues.
If you are using spack-stack and are encountering spack-stack related issues, you will need to submit an issue on their github repository.
You will find a link to their documentation at the github site above.
When is my .bashrc executed? When would it be ignored?
Please review bash(1) and other information on the bash shell on the internet.
I got the message “REMOTE HOST IDENTIFICATION HAS CHANGED!”. What should I do?
You may sometimes get an error message such as the one shown below when attempting to access a remote machine when using ssh/scp/wget or any such command that accesses a remote machine:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the RSA key sent by the remote host is
SHA256:lU91/IcK9rcFKIh1txPP1nfI0+JgNaj9IElGqftsc5H.
Please contact your system administrator.
Add correct host key in /Users/first.last/.ssh/known_hosts to get rid of this message.
'''<big>Offending RSA key in /Users/first.last/.ssh/known_hosts:5</big>'''
RSA host key for [localhost]:55362 has changed and you have requested strict checking.
Host key verification failed.
Most of the time when you get that message, it is likely that the host key on the remote machine has indeed changed, and it is not an attack.
Under rare circumstances it is possible that someone is trying to do what is called a “man-in-the-middle” attack. If you are accessing one of the RDHPCS machines and you can be reasonably certain you can ignore that message, implement the solution given below.
If the remote machine is a non-RDHPCS system you will have to independently verify if the key has actually changed. If it is a well known site such as github etc, they generally post an announcement on their site that the keys have changed. And if you know that the key has changed it is fine to go ahead and implement the solution given below.
After verifying that it is not an attack, the solution is to remove the offending key (shown in the error message) from the ~/.ssh/known_hosts file on the machine where you see the above error. In the highlighted message above, 5 is the line number in the /.ssh/known_hosts file.
In the example shown above, since line 5 is the problem key, you can use your favorite editor and delete that line. Alternatively on a Linux like systems you use the following command:
sed -i.bak -e '5d' ~/.ssh/known_hosts
Where can I find “Operational Data” from WCOSS2 on Hera?
Some operational data from WCOSS2 is available on Hera/HPSS.
However RDHPCS doesn’t keep track of the locations of the operational data stored on Hera/HPSS. Please reach out the NCO SPA team that is responsible for making that data available by contacting them at ‘’’nco.spa@noaa.gov’’’.
My jobs using NCL are no longer working
NCL has decided to switch to Python and have indicated the PyNCL will be replacing NCL.
So if you are used to using:
module load ncl
please load
module load pyncl
That will make NCL version 6.6.2 commands and libraries and headers available. If you use other ncl modules, we found that the gmeta files created will be dodgy, and not show any content with idt, for example.
Also, we have seen some of the programs that use NCL are using the newer features of the Fortran standard, so in addition to loading the “pyncl” module you may consider loading a more recent version of the GNU module.
So if you are working with NCL please use the following module load command:
module load gnu/9.2.0 pyncl
Compile WRF on Hera with Rocky OS
For the earlier versions of WRF model, the user may need following to compile the model on Rocky8 OS. After loading the required modules, user needs to add the following to the CPATH in order to compile the WRF model.
setenv CPATH /usr/include/tirpc:$CPATH
After running the configure command, user needs to add “-ltirpc” to configure.wrf file.
LIB_EXTERNAL = \
-L$(WRF_SRC_ROOT_DIR)/external/io_netcdf -lwrfio_nf -L/apps/netcdf/4.9.2/gnu-9.2.0/lib -lnetcdff -lnetcdf -ltirpc
How do I enable x11 forwarding using PowerShell on a Windows system?
Xming is a popular X Server for Windows, if you don’t have a program such as Xming installed on your local machine you have to install that first. It is a good idea to have Xming running on your machine, so please start that program if you have not done so already.
Assuming Xming is already installed on your system:
Start Powershell and paste the following command :
$env:DISPLAY= 'localhost:0.0'
(you need to type this command each time before using x11 forwarding.)
Now connect to SSH server using -X argument :
ssh username@hostname -XY
X11 forwarding is now enabled on Powershell.
If the remote system is a Linux system you can quickly check if X forwarding is working by running the command xclock.
Port Tunnels
How do I set up an ssh port tunnel?
You can only establish an ssh tunnel from your initial bastion session. If you try to establish a tunnel and see the messages like this:
------------------- bind [127.0.0.1]:57037: Address already in use channel_setup_fwd_listener_tcpip: cannot listen to port: 57037 Could not request local forwarding. -------------------
You will know that you already have an open session, and cannot open a tunnel on this bastion.
To establish a new tunnel, do one of the following:
Close any existing sessions on this bastion, or,
Open a new session using a bastion where you have no existing sessions.
In the steps below, replace First.Last with your own HPC username, and XXXXX with the unique Local Port Number assigned to you when you log in to your specified HPC system. Use the word “localhost” where indicated. It is not a variable, don’t substitute anything else. Before you perform the first step, close all current sessions on the HPC system where you are trying to connect. Once the first session has been opened with port forwarding, any further connections (login via ssh, copy via scp) will work as expected. You are running these commands on your local machine, not within the HPC system terminal.
As long as this ssh window remains open, you will be able to use this forwarded port for data transfers.
1. Find your local port number
To find your unique local port number, log onto your specified HPC system. Make a note of this number - once you’ve recorded it, close all sessions. Note that this number, which is a fixed value for you, will be different on each HPC system.

Note
Open two terminal windows for this process
Local Client Window #1
Enter the appropriate command for your environment. Remember to replace XXXXX with the local port number identified in Step 1 or as needed.
For Windows Power Shell, enter:
ssh -m hmac-sha2-512-etm@openssh.com -XXXXX:localhost:XXXXX First.Last@bastion_hostname
For Mac or Linux, enter:
ssh -L XXXX:localhost:XXXXX First.Last@bastion_hostname
If you will be running X11 applications with x2go or normal terminals, remember to add the -X parameter as follows:
ssh -X -L XXXX:localhost:XXXXX First.Last@bastion_hostname
To verify that the tunnel is working, open another local window in your local machine, and issue the command:
ssh -p XXXX First.Last@localhost
Note that XXXX is your local port number used above, First.Last is your user ID on the RDHPCS systems and localhost is typed as-is.
Note
For a complete list of available bastions by site, check the Bastion Hostnames table.
You should be prompted for your password; enter your PIN + RSA token and you should be able to login. Once you are able to log in, you can log out of that session as that was only for testing the tunnel.
2. Use SCP to Complete the Transfer
Local Client Window #2
Once the session is open, you can use this forwarded port for data transfers, as long as this ssh window is kept open.
Remember that this is the second terminal session opened on your local machine. Once a tunnel has been set up as in Step 1, you can use a client such as WinSCP to do the transfers using that tunnel. Please keep in mind that tunnel will exist only as long as the session opened in Step 1 is kept alive.
Hostname: localhost
Port: your-assigned-port-used-in-Step1-above
File protocol: SFTP
To transfer a file to HPC Systems
For Windows Power Shell, enter:
scp -P XXXXX /local/path/to/file First.Last@localhost:/path/to/file/on/HPCSystems
For Mac or Linux, enter:
rsync <put rsync options here> -e 'ssh -l First.Last -p XXXXX' /local/path/to/files First.Last@localhost:/path/to/files/on/HPCSystems
Note
Your username is case sensitive when used in the scp command. Username should be in the form of First.Last.
To transfer a file from HPC Systems:
For Windows Power Shell, enter:
scp -P XXXXX First.Last@localhost:/path/to/file/on/HPCSystems /local/path/to/file
For Mac or Linux, enter:
rsync <put rsync options here> -e 'ssh -l First.Last -p XXXXX' First.Last@localhost:/path/to/files/on/HPCSystems /local/path/to/files
In either case, you will be asked for a password. Enter the password from your RSA token (not your passphrase). Your response should be your PIN+Token code.
SSH Port Tunnel For PuTTy Windows Systems
PuTTY is an SSH client, used to configure and initiate connection. Navigate to a separate tab to install PuTTY. If you cannot install software on your machine, contact your local systems administrator.
Configuration
Enter host information to configure an SSH Terminal Session:

1. Enter Username In the left pane under Connection, select “Data” and enter your NOAA user name as it appears in your NOAA email address. (Ex: First.Last if your NOAA email is First.Last@noaa.gov). User name is case sensitive - First.Last. If you do not create a username, you will have to enter your user name each time your open a session.

Complete the configuration:
Select “Session” from the top of the left pane.
Select “Save” (between Load and Delete).
Open a First System Session
Open the session to make sure it’s working, and to record your Local Port number to complete the Port Tunneling setup.
Select the configured session from the “Saved Sessions” list. Select Load, then Open.
Enter your unique RSA Passcode.
The RSA passcode is your RSA token PIN followed by 8 digits displayed on your RSA token. The digits must be on display when you press enter, or access will be denied. When you open a new SSH session, wait for the RSA token code to refresh before you enter it.
Find and record your Local Host number.
Click Exit, or close the Putty window to end the session.
Port Tunnel Setup
To enable data transfers, you will need to set up a Port Tunnel.
Open Putty.
Select the session from the Saved Sessions list, then Load.
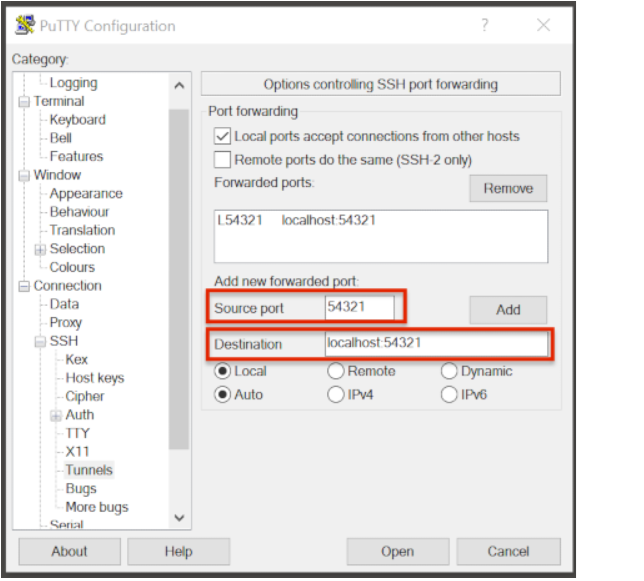
In the left pane under Connection>SSH select Tunnels.
Check Local ports accept connections from other hosts.
In the Source Port field, enter your Local Port number
In the Destination Port field, enter “localhost:<local port number>”, where your local port number matches what was entered in the Source port.
Select Local and Auto Radio Buttons.
Click the Add Button.
To save the configuration change:
In the left pane, select Session.
Select Save.
Select Open to Login and verify that the updated session works correctly.
Create a new Port Tunnel for each SSH system you intend to use. Each one will have a unique Local Port number.
To add extra saved sessions (ex: for another Bastion) for the same system (you already have the Local Port number):
Load your current saved session
Enter the new host name for the other Bastion
Give the new session a new name (ex: Hera- Princeton)
Select Save. The new session will appear in the list of saved sessions.
Select Open to Login and verify the new session works correctly.
How to transfer small files to/from an RDHPCS system?
The Port Tunnelling approach is useful for transferring small amount data to/from RDHPCS systems from your local machine.
Transferring data using scp/WinSCP is a 2 step process:
Establish a Tunnel by following the steps documented here:
Transfer file using WinSCP
See the Data Transfer pages for complete information.
I can no longer transfer files via the port tunnel, please help!
From a given machine, your first login has to establish the port tunnel. If you do not, the port used will be blocked and you cannot establish the port tunnel with subsequent ssh commands. If you cannot use scp to transfer files, look for an error message similar to this the following when you are trying to establish your tunnel:
ssh: connect to host localhost port 2083: Connection refused
The number above will match the port you are trying to use.
To resolve this problem:
Exit all ssh sessions from your host
Restart ssh. This session must have the port tunnel options included
ssh -L XXXX:localhost:XXXX
Try using scp to transfer a file.
Known Issues
Intel MPI Collective Algorithms issue
It has been observed that the default algorithms configured by Intel oneAPI MPI for collective operations are causing instability on AMD systems. Users have reported instances of code hanging, and system monitoring indicates highly uneven Non-Uniform Memory Access (NUMA) load, leading to node performance issues.
To mitigate these issues, a module has been created to set the collective algorithms to empirically tested values. We strongly recommend loading this module whenever utilizing Intel oneAPI for code execution on the Ursa cluster.
module load impi-collective-settings/1.0.0
Please be advised that this module must be loaded in addition to the intel-oneapi-mpi module that your application needs.
Recent User-Facing Changes
Jan 22, 2025: DTNs for Ursa are now available
DTNs and the new file systems for Ursa are now available for your use.
Note
Even though Ursa is not yet available, the new
filesystems /scratch3 and /scratch4, the filesystems for Ursa,
and the DTNs for Ursa are available now.
Note
The /scratch3 and /scratch4 filesystems will be upgraded
in February. There will be a 3-5 day
outage for those file systems at that time.
Currently these two new filesystems are only mounted and accessible from Hera and the new Ursa DTNs.
Host Name |
File System |
Globus Endpoints |
|
|---|---|---|---|
Trusted |
dtn-ursa.fairmont.rdhpcs.noaa.gov |
/scratch[34] |
noaardhpcs#ursa |
Untrusted |
udtn-ursa.fairmont.rdhpcs.noaa.gov |
/scratch[34]/data_untrusted |
noaardhpcs#ursa_untrusted |
Using these new DTNs you can do data transfers to the /scratch3
and /scratch4 filesystems either using Linux tools such
as scp and rsync, or by using Globus Online.
Please see the Overview for more details.
RDHPCS Office Hours
Office Hours are held at regularly. The Support team offers shared solutions to acute and common problems.
Transcripts and recordings can be found in RDHPCS Internal Documentation.