Gaea User Guide

System Overview
Gaea is a NOAA Research and Development High-Performance Computing System (RDHPCS) operated by the National Center for Computational Sciences (NCCS) at the Oak Ridge National Laboratory (ORNL). Gaea is operated as a collaborative effort between the Department of Energy and the National Atmospheric and Oceanic Administration.
The Gaea System consists of two HPE-Cray EX 3000 systems, referred to as C5 and C6. Two high-capacity parallel file systems provide over 150 petabytes of fast access storage. These system-specific filesystems are connected using FDR InfiniBand to the compute and data-transfer resources. The aggregate Gaea system contains a peak calculating capability greater than 20 petaflops (quadrillion floating point operations per second).
NOAA research partners access data remotely through fast interconnections to NOAA’s national research network through peering points at Atlanta and Chicago.
C5
HPE-EX Cray X3000
1,920 compute nodes (2 x AMD EPYC 7H12 2.6GHz 64-cores per socket)
HPE Slingshot Interconnect
264GB DDR4 per node; 500TB total
10.22 PF peak
F5 File System
IBM Spectrum Scale
75 PB
IBM Elastic Storage Server 3500 running GPFS 5.1
C6
HPE-EX Cray X3000
2,048 compute nodes (2 x AMD EPYC 9654 2.4GHz base 96-cores per socket)
HPE Slingshot Interconnect
384GB DDR4 per node; 786TB total
15.1 PF peak (base)
F6
IBM Spectrum Scale
75 PB
IBM Elastic Storage Server 3500 running GPFS 5.1
Gaea is the largest of the NOAA RDHPCS, and is used to study the earth’s notoriously complex weather systems from a variety of angles by enabling scientists:
to understand the relationship between earth modeling and extreme weather, and the atmosphere’s chemical makeup and weather trends.
to investigate the role played by the oceans that cover nearly three-quarters of the globe in long term weather patterns.
Node types
Gaea has three node types: login (front-end, head-node) compute, and data transfer nodes (DTN). The three node types are similar in terms of hardware, but differ in their intended use.
Node Type |
Description |
|---|---|
Login / Front / Head |
You are placed on a login node when you connect to Gaea. This is where you write, edit, and compile your code, manage data submit jobs, etc. You should not launch parallel or threaded jobs from a login node. Login nodes are shared resources. |
Compute |
Most of the nodes on Gaea are compute nodes. Your parallel and threaded jobs execute on the compute nodes, via the srun command. |
DTN |
There are two sets of DTNs. One has the F5 file system mounted, and the other set has F6 mounted. Both have $HOME mounted. These are where extensive I/O operations, large local, and all off-gaea transfers should be done. These nodes are accessible via the es cluster and the dtn_f5_f6 partition. You can include --constraint=f5 or --constraint=f6 when connecting or submitting jobs, to ensure that you are routed to a DTN which has that file system mounted. (Otherwise, this should be selected automatically, based whether your process originated on a C5 or C6 node). |
Compute nodes
Gaea consists of two compute clusters, C5 and C6.
The C5 compute nodes consist of [2x] 64 core AMD EPYC Zen 2 CPUs, with two hardware threads per physical core and 256 GB of physical memory (2 GB per core). C5 supports up to the AVX-2 ISA.
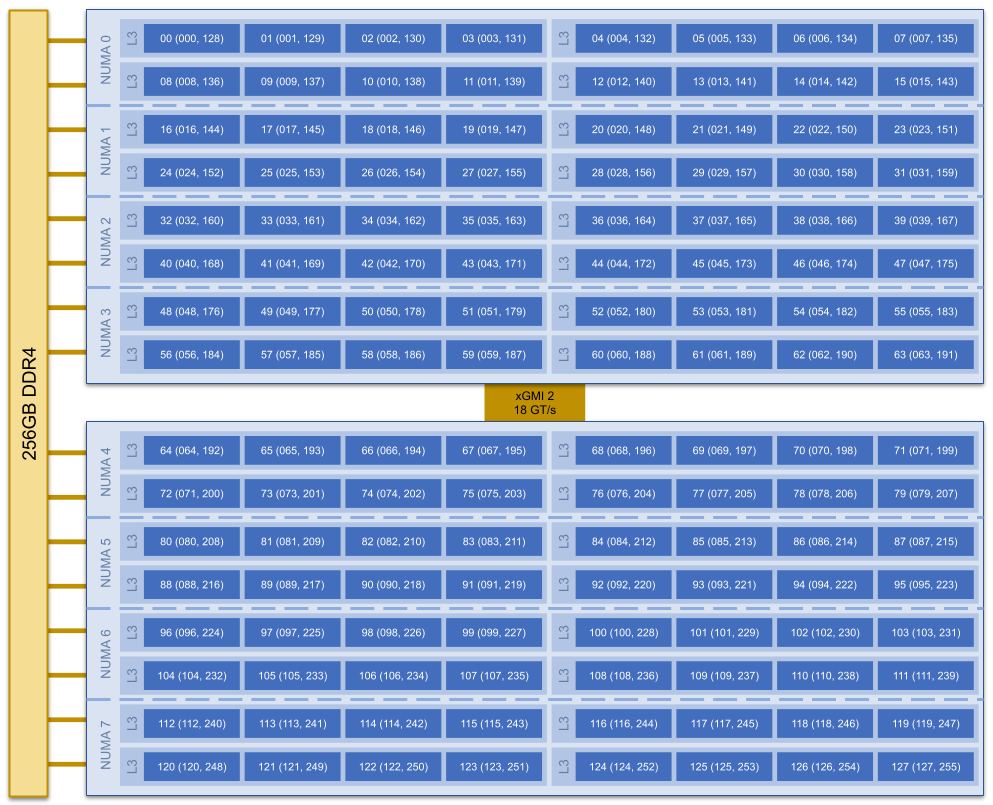
Each C5 compute node has a total of 128 cores, in eight NUMA domains per node. Each group of four cores share an 16 MB L3 cache. Each CPU has eight lanes to the shared 256 GB of node memory.
The C6 compute nodes consist of [2x] 96 core AMD EPYC Zen 4 CPUs, with two hardware threads per physical core and 384 GB of physical memory (2 GB per core). C6 support up to the AVX-512 ISA.

Each C6 compute node has a total of 192 cores, in eight NUMA domains per node. Each group of six cores share a 48 MB L3 cache. Each CPU has 12 lanes to the shared 384 GB of physical memory (2 GB per core).
Login nodes
The Gaea login nodes have a similar architecture to the compute nodes. Each compute cluster has a dedicated set of login nodes.
Host Names |
Node Configuration |
Associated Compute Cluster |
|---|---|---|
|
2x AMD EPYC 7662 64-core (128 cores per node) with 512 GB of memory per node |
C5 |
|
2x AMD EPYC 9654 96-core (192 cores per node) with 512 GB of memory per node |
C6 |
Data transfer nodes
All extensive I/O operations, large local transfers and all off-gaea transfers should be done on a data transfer node (DTN). The DTNs are accessible on the es cluster, under the dtn_f5_f6 partition.
There are two sets of DTNs for gaea - one set with the f5 file system mounted, and another set with the f6 file system mounted. Both sets of DTNs have $HOME mounted.
You can include --constraint=f5 or --constraint=f6 when connecting or submitting jobs to a DTN, to ensure that you are routed to a node which has that file system mounted. Otherwise, you should be automatically routed based on whether your process originated on a C5 or C6 node.
Host Names |
Node Configuration |
File Systems Mounted |
|---|---|---|
|
AMD EPYC 7302 16-core with 256 GB of memory per node |
/gpfs/f5, $HOME |
|
AMD EPYC 7713 64-core with 512 GB of memory per node |
/gpfs/f6, $HOME |
System interconnect
The C5 and C6 nodes are connected with the HPE Slingshot.
Cluster |
NIC |
Total Bandwidth |
|---|---|---|
C5 |
[2x] HPE Slingshot 100 Gbps (12.5 GB/s) |
200 Gbps |
C6 |
[1x] HPE Slingshot 200 Gbps (25.0 GB/s) |
200 Gbps |
File systems
Gaea compute clusters C5 and C6 have their own file system. C5 has
access to F5 mounted at /gpfs/f5. C6 has access to /gpfs/f6.
There are separate sets of DTNs which can
access each file system.
Operating system
The C5 and C6 clusters run the Cray Operating System (COS). COS is based on SUSE Linux Enterprise Server (SLES).
Cluster |
Cray OS Version |
SLES Version |
|---|---|---|
C5 |
3.1.0-28 |
15.5 |
C6 |
3.1.0-28 |
15.5 |
The version of COS and SLES installed on Gaea are updated yearly in the fall.
The version of COS can be found running cat /opt/cray/etc/release/cos-base
and version of SLES can be obtained running lsb-release -a.
See also
- HPE Cray EX Documentation
Documentation specific for the HPE Cray EX 3000 compute system.
- HPE Cray Programming Environment
Documentation that covers the HPE Cray Programming Environment.
- HPE Cray Programming Environment User Guide
The HPE Cray Programming Environment User Guide provides information on how to use the programming environment, including compilers, libraries, and tools.
Connecting
To connect to Gaea, ssh to gaea-rsa.rdhpcs.noaa.gov. For
example,
$ ssh <First.Last>@gaea-rsa.rdhpcs.noaa.gov
For more information on connecting through the Boulder or Princeton bastion, with a CAC, or for your first connection, see Connecting.
By default, the bastion will automatically place a user on a random Gaea C5
login node. If you need to access a specific login node on C6, when prompted
enter Ctrl-C and type the name of a login node or gaea6 for a random
C6 login node:
$ ssh <First.Last>@gaea-rsa.rdhpcs.noaa.gov
Last login: Wed Sep 11 17:20:24 2024 from 140.208.2.184
Welcome to the NOAA RDHPCS.
Attempting to renew your proxy certificate...Proxy certificate has 720:00:00 (30.0 days) left.
Welcome to gaea.rdhpcs.noaa.gov
Gateway to gaea-c5.ncrc.gov and other points beyond
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! RDHPCS Policy states that all user login sessions shall be terminated !!
!! after a maximum duration of seven (7) days. ALL user login sessions will !!
!! be dropped from the Princeton Bastions at 4AM ET / 2AM MT each Monday !!
!! morning, regardless of the duration. Please note: This will NOT impact !!
!! batch jobs, cron scripts, screen sessions, remote desktop, or data !!
!! transfers. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Hostname Description
gaea C5 head nodes
gaea51 C5 head node
gaea52 C5 head node
gaea53 C5 head node
gaea54 C5 head node
gaea55 C5 head node
gaea56 C5 head node
gaea57 C5 head node
gaea58 C5 head node
gaea60 T6 Test access only
gaea61 C6 head node
gaea62 C6 head node
gaea63 C6 head node
gaea64 C6 head node
gaea65 C6 head node
gaea66 C6 head node
gaea67 C6 head node
gaea68 C6 head node
You will now be connected to NOAA RDHPCS: Gaea (NCRC) C5 system.
To select a specific host, hit ^C within 5 seconds.
^CEnter a hostname, or a unique portion of a hostname []:
Data and storage
NFS file systems
Users and projects are given space on the NFS. These locations are ideal for storing user and project applications, executables, and small data files.
Area |
Path |
Permissions |
Quota |
Backups |
Purged |
On Compute Nodes |
|---|---|---|---|---|---|---|
User Home |
|
User set |
50 GB |
Yes |
No |
Yes |
Project Home |
|
Project set |
100 GB |
Yes |
No |
Yes |
GPFS file systems
Each compute cluster, C5 and C6, has its own file system called F5 and F6
respectively, mounted at /gpfs/f5 and /gpfs/f6.
Area |
Path |
Permissions |
Quota |
Backups |
Purged |
On compute nodes |
|---|---|---|---|---|---|---|
F5 Member Work |
|
User set |
N/A |
No |
No |
C5 only |
F5 Project Work |
|
770 |
N/A |
No |
No |
C5 only |
F5 World Work |
|
775 |
N/A |
No |
No |
C5 only |
F6 Member Work |
|
User set |
N/A |
No |
No |
C6 only |
F6 Project Work |
|
770 |
N/A |
No |
No |
C6 only |
F6 World Work |
|
775 |
N/A |
No |
No |
C6 only |
File Compression
GPFS file systems can be enabled for compression. Currently, the F5 file system has this feature turned on, while it is disabled on F6.
The following is the current policy for compression on F5:
/* Macros */
define(excluded_files,(PATH_NAME LIKE '%/.SpaceMan%' OR
PATH_NAME LIKE '%/fs_audit_log/%' OR
PATH_NAME LIKE '%/.snapshots/%' OR
PATH_NAME LIKE '%/.msgq/%'))
/* I.E. Files must be idle for 12 hours before being a candidate for compression */
define(access_buffer_time_passed, ((CURRENT_TIMESTAMP - MODIFICATION_TIME) > (INTERVAL '168' HOURS) AND (CURRENT_TIMESTAMP - ACCESS_TIME) > (INTERVAL '168' HOURS)))
/* Ensure compression on qualified files */
RULE 'compress-large-files-on-hdd' MIGRATE COMPRESS('lz4') FROM POOL 'capacity' WHERE not(excluded_files) AND (KB_ALLOCATED >= 4096) AND access_buffer_time_passed
Additional notes regarding GPFS compression
Users can use the mmchattr command to decompress their files:
mmchattr --compression no -I yes <file>.Files are written to disk uncompressed, and then compression is done upon the execution of our compression cronjob or via an explicit
mmchattrcommand.Compressed files are not decompressed when they are read.
When a compressed file is modified, the entire file is not decompressed. Only the relevant portion will be decompressed, and then re-compressed later upon execution of our cron job or an
mmchattrcommand.There is no direct command to determine the compression ratio applied. Users will need to use commands that return the full size of files (
ls) and divide that by something that shows the on disk space usage of a file (du)
Move data to and from Gaea
The suggested way to move data to and from Gaea is Globus Online. Please review the additional information in Globus Online Data Transfer and Globus Example.
Please review Transferring Data for information on other transfer methods available.
Programming environment
Gaea users are provided with many pre-installed software packages and scientific libraries. Environment management tools are used to handle necessary changes to the shell.
Please refer to the HPE Cray Programming Environment and the HPE Cray Programming Environment User Guide documentation for more detail.
Environment Modules
Environment modules are provided through Lmod, a Lua-based module system for
dynamically altering shell environments. By managing changes to the shell’s
environment variables (such as PATH, LD_LIBRARY_PATH, and
PKG_CONFIG_PATH), Lmod allows you to alter the software available in your
shell environment without the risk of creating package and version combinations
that cannot coexist in a single environment.
General Usage
The interface to Lmod is provided by the module command:
Command |
Description |
|---|---|
|
Shows a terse list of the currently loaded modules |
|
Shows a table of the currently available modules |
|
Shows help information about
|
|
Shows the environment changes made by the
|
|
Searches all possible modules according to <string> |
|
Loads the given |
|
Adds |
|
Removes |
|
Unloads all modules |
|
Resets loaded modules to system defaults |
|
Reloads all currently loaded modules |
Searching for Modules
Modules with dependencies are only available when the underlying dependencies,
such as compiler families, are loaded. Thus, module avail will only display
modules that are compatible with the current state of the environment. To
search the entire hierarchy across all possible dependencies, the spider
sub-command can be used as summarized in the following table.
Command |
Description |
|---|---|
|
Shows the entire possible graph of modules |
|
Searches for modules named
|
|
Searches for a specific version
of |
|
Searches for modulefiles
containing |
Compilers
Cray, AMD, NVIDIA, and GCC compilers are provided through modules on Gaea.
There is also a system/OS versions of GCC available in /usr/bin. The
table below lists details about each of the module-provided compilers. Please
see the Compiling section for more detailed information on
how using these modules to compile.
MPI
The MPI implementation available on Gaea is Cray MPICH.
Compiling
Compilers
Cray, AMD, NVIDIA, and GCC compilers are provided through modules on Gaea.
There is also a system/OS version of GCC available in /usr/bin. The
table below lists details about each of the module-provided compilers.
Important
It is highly recommended to use the Cray compiler wrappers (cc, CC, and ftn) whenever possible. See the next section for more details.
Vendor |
Programming Environment |
Compiler Module |
Language |
Compiler Wrapper |
Compiler |
|---|---|---|---|---|---|
AMD |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
Cray |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
GNU |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
Intel |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
NVIDIA |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
Note
The gcc-native compiler module was introduced in the December 2023
release of the HPE/Cray Programming Environment (CrayPE) and replaces
gcc. gcc provides GCC installations that were packaged within
CrayPE, while gcc-native provides GCC installations outside of CrayPE.
Cray programming environment and compiler wrappers
Cray provides PrgEnv-<compiler> modules (for example, PrgEnv-cray) that
load compatible components of a specific compiler toolchain. The components
include the specified compiler as well as MPI, LibSci, and other libraries.
Loading the PrgEnv-<compiler> modules also defines a set of compiler
wrappers for that compiler toolchain that automatically add include paths and
link in libraries for Cray software. Compiler wrappers are provided for C
(cc), C++ (CC), and Fortran (ftn).
For example, to load the Intel programming environment do:
$ module load PrgEnv-intel
This module will setup your programming environment with paths to software and libraries that are compatible with Intel host compilers.
Note
Use the -craype-verbose compiler flag to display the full include and link
information used by the Cray compiler wrappers. This must be called on a
file, for example CC -craype-verbose test.cpp.
Dynamic linking
All executables built on Gaea are dynamically linked, which is currently the only supported linking method. This means that the executable will not contain the libraries it depends on, but will instead use the libraries available on the system at runtime. Dynamic linking allows for smaller executable sizes and enables sharing libraries between multiple executables, saving disk space and memory. However, it also means that the executable may not run if the required libraries are not available at runtime. Dynamic linking is performed using the Executable and Linking Format (ELF) standard. The ELF format is a common standard for executable files on Unix-like systems, including Linux, and is used to define the structure of executable files,
To help ensure the correct libraries are available at runtime, the dynamic
loader (ld.so, see ld.so(8)) will use location
information stored in the executable (if available, known as RPATH), then
search the directories listed in the environment variable LD_LIBRARY_PATH,
and finally the directories listed in /etc/ld.so.conf. The first
instance of a specific library found in the hierarchy of locations will be
used.
To embed the location of a library within the executable’s RPATH, you can
use the -Wl,-rpath,<path> option when compiling, where <path> is the
path to the directory that contains the library. For example, to add the
directory /path/to/some/lib to the executable’s RPATH, you would run:
$ cc -Wl,-rpath,/path/to/some/lib -L/path/to/some/lib -lsomelib myprogram.c -o myprogram
If you need to specify multiple paths to RPATH you can either specify
multiple -Wl,-rpath,<path> options, or separate the paths with a colon
(:). For example:
$ cc -Wl,-rpath,/path/to/lib1:/path/to/lib2 -L/path/to/lib1 -L/path/to/lib2 -lsomelib1 -lsomelib2 myprogram.c -o myprogram
This will embed both directories in the executable’s RPATH.
On systems that use the Cray Programming Environment, the dynamic loader is
configured to always search the directory /opt/cray/pe/lib64. This
directory contains the default Cray libraries. Because this directory is
included in the search path, switching the module environment does not
completely change the run-time environment. As an example, we’ll look at using
a non-default MPI library. The mpi_test.c code has the following:
#include <mpi.h>
#include <stdio.h>
int
main(int argc, char** argv)
{
char mpi_version_string[MPI_MAX_LIBRARY_VERSION_STRING];
int mpi_ver_len;
MPI_Init(NULL, NULL);
MPI_Get_library_version(mpi_version_string, &mpi_ver_len);
printf("MPICH Build Version: %s\n", MPICH_VERSION);
printf("MPICH Run Version: %s\n", mpi_version_string);
MPI_Finalize();
return 0;
}
We compile and run this code using the default cray-mpich module:
$ cc -o mpi_test mpi_test.c
$ srun -n 1 ./mpi_test
MPICH Build Version: 3.4a2
MPICH Run Version: MPI VERSION : CRAY MPICH version 8.1.32.110 (ANL base 3.4a2)
We see the build version, MPICH_VERSION, matches the library version,
as returned from MPI_Get_library_version.
In this second example, we use a different version of the cray-mpich
module.
$ module swap cray-mpich/9.0.0
The following have been reloaded with a version change:
1) cray-mpich/8.1.32 => cray-mpich/9.0.0
$ cc -o mpi_test mpi_test.c
$ srun -n 1 ./mpi_test
MPICH Build Version: 4.1.2
MPICH Run Version: MPI VERSION : CRAY MPICH version 8.1.31.9 (ANL base 3.4a2)
As we can see, the library used to build and run the executable are different.
We used version 4.1.2 when building, but due to finding the MPI library in
/opt/cray/pe/lib64, we used the default 3.4a2 version when running.
As mentioned above, you can set the LD_LIBRARY_PATH environment variable to
adjust which libraries are loaded at run time. The directories listed in
LD_LIBRARY_PATH take precedence over the libraries included in
/etc/ld.so.config, which includes /opt/cray/pe/lib64. This is
useful if you have already built an executable, but did not supply the linker
flags to modify the RPATH. HPE suggests prepending to LD_LIBRARY_PATH the
variable CRAY_LD_LIBRARY_PATH. In the following example, we prepend
CRAY_LD_LIBRARY_PATH to the LD_LIBRARY_PATH environment variable.
$ module swap cray-mpich/9.0.0
The following have been reloaded with a version change:
1) cray-mpich/8.1.32 => cray-mpich/9.0.0
$ cc -o mpi_test mpi_test.c
$ export LD_LIBRARY_PATH=${CRAY_LD_LIBRARY_PATH}:${LD_LIBRARY_PATH}
$ srun -n 1 ./mpi_test
MPICH Build Version: 4.1.2
MPICH Run Version: MPI VERSION : CRAY MPICH version 9.0.0.113 (ANL base 4.1.2)
We see prepending to LD_LIBRARY_PATH allows the loader to find the
same MPI library (4.1.2) at run time.
While prepending to LD_LIBRARY_PATH allows using the same library at run
time, you can still get an unexpected library, based on what is added to the
LD_LIBRARY_PATH. In the next example, we’ll go back to our first example,
but switch the MPICH module and then set LD_LIBRARY_PATH.
$ cc -o mpi_test mpi_test.c
$ srun -n 1 ./mpi_test
MPICH Build Version: 3.4a2
MPICH Run Version: MPI VERSION : CRAY MPICH version 8.1.32.110 (ANL base 3.4a2)
$ module swap cray-mpich/9.0.0
The following have been reloaded with a version change:
1) cray-mpich/8.1.32 => cray-mpich/9.0.0
$ srun -n 1 ./mpi_test
MPICH Build Version: 3.4a2
MPICH Run Version: MPI VERSION : CRAY MPICH version 9.0.0.113 (ANL base 4.1.2)
Here we see the loader found the 4.1.2 MPICH library due to setting the
LD_LIBRARY_PATH variable, showing that setting LD_LIBRARY_PATH can lead to
using an unintended library.
Adjusting the executable’s RPATH allows for adding an explicit,
higher-precedent search path. The method requires using -Wl,-rpath,<path>
when linking the executable. This example shows how to use
-Wl,-rpath,$MPICH_DIR/lib when compiling.
$ module swap cray-mpich/9.0.0
The following have been reloaded with a version change:
1) cray-mpich/8.1.32 => cray-mpich/9.0.0
$ cc -Wl,-rpath,$MPICH_DIR/lib -o mpi_test mpi_test.c
$ srun -n 1 ./mpi_test
MPICH Build Version: 4.1.2
MPICH Run Version: MPI VERSION : CRAY MPICH version 9.0.0.113 (ANL base 4.1.2)
Here we see the version used when building the executable (4.1.2), matches the version used when running. The loader finds the correct library using the compiled-in RPATH because, as was mentioned above, library path information stored in the executable via RPATH takes precedence when attempting to satisfy references.
Adding library paths to the executable’s RPATH takes precedence over the
directories listed in LD_LIBRARY_PATH and /etc/ld.so.config. In
the next example, we build the executable with one MPICH version, switch the
MPICH module to a different version from the default and the version used to
build the executable before setting LD_LIBRARY_PATH.
$ module swap cray-mpich/9.0.0
The following have been reloaded with a version change:
1) cray-mpich/8.1.32 => cray-mpich/9.0.0
$ cc -Wl,-rpath,$MPICH_DIR/lib -o mpi_test mpi_test.c
$ srun -n 1 ./mpi_test
MPICH Build Version: 4.1.2
MPICH Run Version: MPI VERSION : CRAY MPICH version 9.0.0.113 (ANL base 4.1.2)
$ module swap cray-mpich/8.1.28
The following have been reloaded with a version change:
1) cray-mpich/9.0.0 => cray-mpich/8.1.28
$ export LD_LIBRARY_PATH=${CRAY_LD_LIBRARY_PATH}:${LD_LIBRARY_PATH}
$ srun -n 1 ./mpi_test
MPICH Build Version: 4.1.2
MPICH Run Version: MPI VERSION : CRAY MPICH version 9.0.0.113 (ANL base 4.1.2)
As we can see, adding the library path to RPATH allows the executable to find the desired MPICH library, even though we set LD_LIBRARY_PATH. Explicitly setting the RPATH is the preferred method to use if you need to use a specific library version.
Note
You can inspect which libraries an executable will use at run time by using
the ldd command. For example, we could have run ldd
mpi_test above to list all the libraries. You can also use
readelf to inspect the executable’s RPATH. For example,
readelf -d mpi_test | grep -i rpath.
See also
- Executable and Linking Format (ELF) - Dynamic Linking
A good overview of the ELF format and how dynamic linking works.
- HPE Cray PE User Guide - Swapping other programming environment components
This is HPE’s supported documentation on how to manage which libraries are used at run time. In the documentation, HPE discusses an additional environment variable
PE_LD_LIBRARY_PATH. This variable is new in the HPE Cray Programming Environment version 25.03. The older library version do not use this variable to adjust theLD_LIBRARY_PATHenvironment variable.
Running jobs
Computational work on Gaea is performed by jobs. Jobs typically consist of several components:
A batch submission script
A binary executable
A set of input files for the executable
A set of output files created by the executable
In general, the process for running a job is:
prepare executables and input files
write a batch script
submit the batch script to the batch scheduler
optionally monitor the job before and during execution
The following sections describe in detail how to create, submit, and manage jobs for execution on Gaea. Gaea uses SchedMD’s Slurm Workload Manager as the batch scheduling system.
Login vs Compute Nodes
Recall from the System Overview that Gaea contains two node types: Login and Compute. When you connect to the system, you are placed on a login node. Login nodes are used for tasks such as code editing, compiling, etc. They are shared among all users of the system, so it is not appropriate to run tasks that are long or computationally intensive on login nodes. Users should also limit the number of simultaneous tasks on login nodes (e.g. concurrent tar commands, parallel make).
Compute nodes are the appropriate place for long-running, computationally-intensive tasks. When you start a batch job, your batch script (or interactive shell for batch-interactive jobs) runs on one of your allocated compute nodes.
Warning
Compute-intensive, memory-intensive, or other disruptive processes running on login nodes may be killed without warning.
Slurm
Gaea uses SchedMD‘s Slurm Workload Manager to schedule and manage jobs. A few items related to Slurm are below. See our local Slurm overview or the official Slurm documentation for more information.
Slurm documentation is also available for each command via the man utility, and on the web at https://slurm.schedmd.com/man_index.html.
See also
- Slurm documentation
The official SchedMD Slurm documentation.
Slurm clusters
Slurm on Gaea is configured as a federation. This places the different Gaea
compute, login and DTNs into different clusters. The default behavior of the
Slurm commands is to show information about the cluster the command is run
on. The user must specify the cluster via the --clusters (or -M)
command-line option to show information about the other clusters.
For example, to show the jobs in the queue on the C6 cluster, you would run
squeue --clusters=c6 or squeue -M c6.
Users can set the SLURM_CLUSTER environment variable to the cluster they
want the a different default set of clusters. For example, if the user wants
information for the ES and C5 clusters, they would set export
SLURM_CLUSTERS=c5,es.
The current Slurm clusters are:
Cluster |
Nodes |
|---|---|
c5 |
C5 compute nodes |
c6 |
C6 compute nodes |
es |
All login and DTN nodes |
Batch Scripts
The most common way to interact with the batch system is via batch scripts. A batch script is simply a shell script with added directives to request various resources from or provide certain information to the scheduling system. Aside from these directives, the batch script is simply the series of commands needed to set up and run your job.
To submit a batch script, use the command sbatch myjob.sl, where
myjob.sl is the bach script.
Consider the following batch script:
1#!/bin/bash
2#SBATCH -M c5
3#SBATCH -A ABC123
4#SBATCH -J RunSim123
5#SBATCH -o %x-%j.out
6#SBATCH -t 1:00:00
7#SBATCH -p batch
8#SBATCH -N 1024
9
10cd /gpfs/f5/${SBATCH_ACCOUNT}/scratch/$USER/abc123/Run.456
11cp /gpfs/f5/${SBATCH_ACCOUNT/proj-shared/abc123/RunData/Input.456 ./Input.456
12srun ...
13cp my_output_file /gpfs/f5/${SBATCH_ACCOUNT}/proj-shared/abc123/RunData/Output.456
In the script, Slurm directives are preceded by #SBATCH, making them appear
as comments to the shell. Slurm looks for these directives through the first
non-comment, non-whitespace line. Options after that will be ignored by Slurm
(and the shell).
Line |
Description |
|---|---|
1 |
Shell interpreter line |
2 |
Gaea cluster to use |
3 |
RDHPCS project to charge |
4 |
Job name |
5 |
Job standard output file ( |
6 |
Walltime requested (in |
7 |
Partition (queue) to use |
8 |
Number of compute nodes requested |
9 |
Blank line |
10 |
Change into the run directory |
11 |
Copy the input file into place |
12 |
Run the job ( add layout details ) |
13 |
Copy the output file to an appropriate location. |
Interactive Jobs
Most users will find batch jobs an easy way to use the system, as they allow you to “hand off” a job to the scheduler, allowing them to focus on other tasks while their job waits in the queue and eventually runs. Occasionally, it is necessary to run interactively, especially when developing, testing, modifying or debugging a code.
Since all compute resources are managed and scheduled by Slurm, you can’t
simply log into the system and immediately begin running parallel codes
interactively. Rather, you must request the appropriate resources from Slurm
and, if necessary, wait for them to become available. This is done through an
“interactive batch” job. Interactive batch jobs are submitted with the
salloc command. You request resources using the same options that
are passed via #SBATCH in a regular batch script (but without the
#SBATCH prefix). For example, to request an interactive batch job with the
same resources that the batch script above requests, you would use salloc -A
ABC123 -J RunSim123 -t 1:00:00 -p batch -N 1024. Note there is no option for
an output file if you are running interactively, so standard output and
standard error will be displayed to the terminal.
Warning
Indicating your shell in your salloc command, for example
salloc ... /bin/bash, is NOT recommended. This will cause your
compute job to start on a login node, rather than automatically moving you
to a compute node.
Common Slurm Options
The table below summarizes options for submitted jobs. Unless otherwise noted,
they can be used for either batch scripts or interactive batch jobs. For
scripts, they can be added on the sbatch command line or as a
#SBATCH directive in the batch script. (If they’re specified in both
places, the command line takes precedence.) This is only a subset of all
available options. Check the Slurm Man Pages for a more complete list.
Option |
Example Usage |
Description |
|---|---|---|
|
|
Specifies the project to which the job should be charged |
|
|
Request 1024 nodes for the job |
|
|
Request a walltime of 4 hours. Walltime requests can be specified as minutes, hours:minutes, hours:minutes:seconds, days-hours, days-hours:minutes, or days-hours:minutes:seconds |
|
|
Number of active hardware threads per core. Can be 1 or 2 (1 is default). Must be used if using
|
|
|
Specify job dependency (in this example, this job cannot start until job 12345 exits with an exit code of 0. See the Job Dependency section for more information. |
|
|
Specify the job name (this will show up in queue listings) |
|
|
File where job STDOUT will be directed (%j will be replaced with the job ID). If no -e option is specified, job STDERR will be placed in this file, too. |
|
|
File where job STDERR will be directed (%j will be replaced with the job ID). If no -o option is specified, job STDOUT will be placed in this file, too. |
|
|
Send email for certain job actions. Can be a comma-separated list. Actions include BEGIN, END, FAIL, REQUEUE, INVALID_DEPEND, STAGE_OUT, ALL, and more. |
|
|
Email address to be used for notifications. |
|
|
Instructs Slurm to run a job on nodes that are part of the specified reservation |
|
|
Instructs Slurm to reserve a specific number of cores per node (default is 8). Reserved cores cannot be used by the application. |
|
|
Instructs Slurm to run a job on nodes that are associated with the specified constraint/feature |
|
|
Send the given signal to a job the
specified time (in seconds) seconds
before the job reaches its walltime. The
signal can be by name or by number (i.e.
both 10 and USR1 would send SIGUSR1).
Signaling a job can be used, for
example, to force a job to write a
checkpoint just before Slurm kills the
job (note that this option only sends the
signal; the user must still make sure
their job script traps the signal and
handles it in the desired manner).
When used with
sbatch, the signal
can be prefixed by “B:” (e.g.
--signal=B:USR1@300) to tell Slurm to
signal only the batch shell; otherwise
all processes will be signaled. |
Slurm Environment Variables
Slurm reads a number of environment variables, many of which can provide the same information as the job options noted above. We recommend using the job options rather than environment variables to specify job options, as it allows you to have everything self-contained within the job submission script, instead than having to remember what options you set for a given job.
Slurm also provides a number of environment variables within your running job. The following table summarizes those that may be particularly useful within your job:
Variable |
Description |
|---|---|
|
The directory from which the batch job was
submitted. By default, a new job starts in your
home directory. You can get back to the
directory of job submission with
|
|
The account name supplied by the user. |
|
The job’s full identifier. A common use for
|
|
The number of nodes requested. |
|
The job name supplied by the user. |
|
The list of nodes assigned to the job. |
Job States
A job will transition through several states during its lifetime. Common ones include:
State Code |
State |
Description |
|---|---|---|
CA |
Canceled |
The job was canceled (could’ve been by the user or an administrator) |
CD |
Completed |
The job completed successfully (exit code 0) |
CG |
Completing |
The job is in the process of completing (some processes may still be running) |
PD |
Pending |
The job is waiting for resources to be allocated |
R |
Running |
The job is currently running |
Job Reason Codes
In addition to state codes, jobs that are pending will have a reason code to explain why the job is pending. Completed jobs will have a reason describing how the job ended. Some codes you might see include:
Reason |
Meaning |
|---|---|
Dependency |
Job has dependencies that have not been met |
JobHeldUser |
Job is held at user’s request |
JobHeldAdmin |
Job is held at system administrator’s request |
Priority |
Other jobs with higher priority exist for the partition/reservation |
Reservation |
The job is waiting for its reservation to become available |
AssocMaxJobsLimit |
The job is being held because the user/project has hit the limit on running jobs |
ReqNodeNotAvail |
The job requested a particular node, but it’s currently unavailable (it’s in use, reserved, down, draining, etc.) |
JobLaunchFailure |
Job failed to launch (could due to system problems, invalid program name, etc.) |
NonZeroExitCode |
The job exited with some code other than 0 |
Many other states and job reason codes exist. For a more complete description, see the squeue(1) man page.
Scheduling Policy
In a simple batch queue system, jobs run in a first-in, first-out (FIFO) order. This can lead to inefficient use of the system. If a large job is the next to run, a strict FIFO queue can cause nodes to sit idle while waiting for the large job to start. Backfilling would allow smaller, shorter jobs to use those resources that would otherwise remain idle until the large job starts. With the proper algorithm, they would do so without impacting the start time of the large job. While this does make more efficient use of the system, it encourages the submission of smaller jobs.
Job priority
Slurm on Gaea uses the Slurm priority/multifactor plugin to calculate a job’s priority. The factors used are:
- Age
the length of time a job has been waiting in the queue, eligible to be scheduled
- Fair-share
the difference between the portion of the computing resources that has been promised (allocation) and the amount of resources that has been consumed. Gaea uses the classic fairshare algorithm
- QOS
a factor associated with each Quality Of Service (QOS)
Note
Only the QOSes on the compute clusters will affect a job’s priority value.
QOS |
Priority Factor |
Usage Factor |
Max Walltime |
Clusters |
Description |
|---|---|---|---|---|---|
normal |
0.85 |
1.00 |
16 hours |
C5, C6, ES |
The default QOS for compute cluster jobs. |
debug |
1.00 |
1.00 |
1 hour |
C5, C6 |
The highest priority QOS. Useful for short, non-production work. |
urgent |
0.95 |
1.00 |
16 hours |
C5, C6 |
QOS to allow groups to prioritize their project’s jobs. |
windfall |
0.00 |
0.00 |
16 hours |
C5, C6, ES |
Lowest priority as only age and fair-share are used in priority calculation. The windfall QOS will also keep jobs from affecting the project’s overall fair-share. |
dtn |
0.00 |
1.00 |
16 hours |
ES |
Default QOS for all jobs executed on gaea DTN’s (data transfer nodes). |
ppan |
0.00 |
1.00 |
16 hours |
ES |
QOS to indicate job is performing a transfer to/from GFDL/PPAN. Jobs will be paused when PPAN is in a maintenance period. |
hpss |
0.00 |
1.00 |
16 hours |
ES |
QOS to indicate job is performing a transfer to/from NESCC HPSS. Jobs will be paused when HPSS is in a maintenance period. |
Note
Interactive jobs, that is jobs started with the salloc command,
will have the QOS interactive automatically added unless the --qos
option is used. The interactive QOS has the same priority factor as the
debug QOS. However, users can only have a single Interactive job at
any time.
Note
The priority and usage factors for all QOSes can be found using the command sacctmgr show qos format=name,priority,usagefactor,maxwall.
The command sprio can be used to see the current priority, and the age, fair-share, and qos factors for a specific jobs.
The command sshare will show the current shares (allocation), usage, and fair-share factors for all projects (allocations).
Partitions
Cluster |
Name Name |
Nodes |
Time |
Description |
||
|---|---|---|---|---|---|---|
Min |
Max |
Default |
Maximum |
|||
C5 and C6 |
batch |
1 |
512 |
12:00:00 |
16:00:00 |
Default for jobs under the max node count. |
novel |
513 |
max |
12:00:00 |
16:00:00 |
Default for jobs above the minimum node count. This partition is only enabled after a system maintenance. Please alert the HD if you need to run a job in this partition. |
|
ES |
eslogin_c5 |
1 |
1 |
12:00:00 |
16:00:00 |
These jobs will run on the C5 login nodes. |
eslogin_c6 |
1 |
1 |
12:00:00 |
16:00:00 |
These jobs will run on the C6 login nodes. |
|
dtn_f5_f6 |
1 |
1 |
12:00:00 |
16:00:00 |
These jobs will
run on the DTN
nodes. There are
separate subsets
of nodes with
either F5 or F6
mounted, which
can be selected
by using the
|
|
cron_c5 |
1 |
1 |
12:00:00 |
16:00:00 |
Required partition for jobs run under scron on the C5 login nodes. |
|
cron_c6 |
1 |
1 |
12:00:00 |
16:00:00 |
Required partition for jobs run under scron on the C6 login nodes. |
|
Note
The partition information above, and additional information can be listed using the scontrol --cluster <cluster> show partition where <cluster> is the name of one of the available clusters.
Job Dependencies
Frequently, a job will need data from some other job in the queue, but it’s
nonetheless convenient to submit the second job before the first finishes.
Slurm allows you to submit a job with constraints that will keep it from
running until these dependencies are met. These are specified with the -d
option to Slurm. Common dependency flags are summarized below. In each of these
examples, only a single jobid is shown but you can specify multiple job IDs as
a colon-delimited list (i.e. #SBATCH -d afterok:12345:12346:12346). For the
after dependency, you can optionally specify a +time value for each
jobid.
Flag |
Meaning (for the dependent job) |
|---|---|
|
The job can start after the specified jobs
start or are canceled. The optional |
|
The job can start after the specified jobs have ended (regardless of exit state) |
|
The job can start after the specified jobs terminate in a failed (non-zero) state |
|
The job can start after the specified jobs complete successfully (i.e. zero exit code) |
|
Job can begin after any previously-launched job with the same name and from the same user have completed. In other words, serialize the running jobs based on username+jobname pairs. |
Monitoring and modifying batch jobs
Holding and releasing jobs
Sometimes you may need to place a hold on a job to keep it from starting. For
example, you may have submitted it assuming some needed data was in place but
later realized that data is not yet available. You can do this with the
scontrol hold command. Later, when the data is ready, you can release the
job (i.e. tell the system that it’s now OK to run the job) with the scontrol
release command. For example:
|
Place job 12345 on hold |
|
Release job 12345 (i.e. tell the system it’s OK to run it) |
Changing job parameters
There may also be occasions where you want to modify a job that’s waiting in
the queue. For example, perhaps you requested 2,000 nodes but later realized
this is a different data set and only needs 1,000 nodes. You can use the
scontrol update command for this. For example:
|
Change job 12345’s node request to 1000 nodes |
|
Change job 12345’s max walltime to 4 hours |
Cancel or signal a job
In addition to the --signal option for the sbatch/salloc commands
described above, the scancel command can be
used to manually signal a job. Typically, this is used to remove a job from the
queue. In this use case, you do not need to specify a signal and can simply
provide the jobid (i.e. scancel 12345). If you want to send some other
signal to the job, use scancel the with the -s option. The -s
option allows signals to be specified either by number or by name. Thus, if you
want to send SIGUSR1 to a job, you would use scancel -s 10 12345 or
scancel -s USR1 12345.
View the queue
The squeue command is used to show the batch queue. You can filter the
level of detail through several command-line options. For example:
|
Show all jobs currently in the queue |
|
Show all of your jobs currently in the queue |
Get job accounting information
The sacct command gives detailed information about jobs currently in the
queue and recently-completed jobs. You can also use it to see the various steps
within a batch jobs.
|
Show all jobs ( |
|
Show all of your jobs, and show
the individual steps (since
there was no |
|
Show all job steps that are part of job 12345 |
|
Show all of your jobs since 1 PM on July 1, 2022 using a particular output format |
Get detailed job information
In addition to holding, releasing, and updating the job, the scontrol
command can show detailed job information via the show job subcommand. For
example, scontrol show job 12345.
Srun
The default job launcher for Gaea is srun . The srun command is used to execute an MPI binary on one or more compute nodes in parallel.
Srun Format
$ srun [OPTIONS... [executable [args...]]]
Single Command (non-interactive)
$ srun -A <project_id> -t 00:05:00 -p <partition> -N 2 -n 4 --ntasks-per-node=2 ./a.out
<output printed to terminal>
The job name and output options have been removed since stdout/stderr are typically desired in the terminal window in this usage mode.
srun accepts the following common options:
|
Number of nodes |
|
Total number of MPI tasks (default is 1) |
|
Logical cores per MPI task (default is 1).
When used with |
|
Bind tasks to CPUs.
|
|
In task layout, use the specified maximum
number of hardware threads per core
(default is 1; there are 2 hardware
threads per physical CPU core).
Must also be set in |
|
Specifies the distribution of MPI ranks
across compute nodes, sockets (L3
regions), and cores, respectively.
The default values are
|
|
If used without |
Software
Gaea has several software and libraries available. These are accessible using
the Lmod module system. Use the module
avail and module spider commands to see the list of software. Only modules
in the /opt and /sw areas are supported at the RDHPCS level.
Projects and users can install software and software stacks in their user or
project spaces, that is in /ncrc/home[12]/$USER/, /usw, and
/ncrc/proj locations. Those projects and users then maintain and
support the software and software stacks.
Debugging
Linaro DDT
Linaro DDT is an advanced debugging tool used for scalar, multi-threaded, and large-scale parallel applications. In addition to traditional debugging features (setting breakpoints, stepping through code, examining variables), DDT also supports attaching to already-running processes and memory debugging. In-depth details of DDT can be found in the official DDT User Guide, and instructions for how to use it on RDHPCS systems can be found on the Debugging Software page. DDT is the RDHPCS’s recommended debugging software for large parallel applications.
One of the most useful features of DDT is its remote debugging feature. This allows you to connect to a debugging session on RDHPCS systems from a client running on your workstation. The local client provides much faster interaction than you would have if you use the graphical client on RDHPCS systems. For guidance in setting up the remote client see the Debugging Software page.
GDB
GDB, the GNU Project Debugger (GDB), is a command-line debugger useful for traditional debugging and investigating code crashes. GDB lets you debug programs written in Ada, C, C++, Objective-C, Pascal (and many other languages).
GDB is available on Gaea under all compiler families:
module load gdb
To use GDB to debug your application run:
gdb ./path_to_executable
Additional information about GDB usage can be found in the GDB Documentation.
GDB4HPC
gdb4hpc is a GDB-based parallel debugger, developed by HPE Cray. It allows programmers to either launch an application or attach to an already-running application that was launched with srun, to debug the parallel code in command-line mode.
Information on GDB4HPC and other tools available in the HPE Cray Programming Environment is available, including a tutorial.
Valgrind4hpc
Valgrind4hpc is a Valgrind-based debugging tool to aid in the detection of memory leaks and errors in parallel applications. Valgrind4hpc aggregates any duplicate messages across ranks to help provide an understandable picture of program behavior. Valgrind4hpc manages starting and redirecting output from many copies of Valgrind, as well as deduplicating and filtering Valgrind messages. If your program can be debugged with Valgrind, it can be debugged with Valgrind4hpc.
Valgrind4hpc is available on Gaea under all compiler families:
module load valgrind4hpc
Additional information about Valgrind4hpc usage can be found in the HPE Cray Programming Environment User Guide.
Profiling
HPE Performance Analysis Tools
The HPE Performance Analysis Tools are a suite of utilities that enable users to capture and analyze performance data generated during program execution. These tools provide an integrated infrastructure for measurement, analysis, and visualization of computation, communication, I/O, and memory utilization to help users optimize programs for faster execution and more efficient computing resource usage.
There are three programming interfaces available: (1) Perftools-lite, (2)
Perftools, and (3) Perftools-preload.
Below are two examples that generate an instrumented executable using
Perftools, which is an advanced interface that provides full-featured data
collection and analysis capability, including full traces with timeline
displays.
The first example generates an instrumented executable using a PrgEnv-amd
build:
module load PrgEnv-amd
module load perftools
export CXXFLAGS='-ggdb -O3 -std=c++17 –Wall'
export LD='CC'
export LDFLAGS="${CXXFLAGS}
make clean
make
pat_build -g io,mpi -w -f <executable>
The pat_build command in the above examples generates an instrumented
executable with +pat appended to the executable name (e.g.,
hello_jobstep+pat).
When run, the instrumented executable will trace HIP, I/O, MPI, and all user
functions and generate a folder of results (e.g.,
hello_jobstep+pat+39545-2t).
To analyze these results, use the pat_report command, e.g.:
pat_report hello_jobstep+pat+39545-2t
The resulting report includes profiles of functions, profiles of maximum function times, details on load imbalance, details on program energy and power usages, details on memory high water mark, and more.
More detailed information on the HPE Performance Analysis Tools can be found in the HPE Performance Analysis Tools User Guide.
Tips and tricks
GPFS (F5) Performance
The Gaea system intermittently has issues with the GPFS F5 performance. This typically appears as file operations hangs in interactive sessions, and as jobs taking longer than normal to complete, or time out, as any jobs on Gaea currently experience longer than normal run times. While we do not yet have an underlying cause for this, we have found certain changes to the user’s interactions and workflows that use the GPFS F5 file system help alleviate the problem.
Files accesses by multiple jobs
Users should not have multiple batch jobs access the same files. This is typically done using hard- or soft-links. Accessing the same file from multiple batch jobs increases the load on the metadata servers (MDS), and can lead to a MDS locking up that affecting all files served on that MDS.
Users should clean up files after the job runs successfully to ensure the file system has enough free space for all user’s jobs.
Software Environments
Users should not store software environments, for example Conda, Python, and Spack, on the GPFS file system. These environments have many small files that will be accessed from multiple compute nodes when used in batch jobs.
These environments should be stored in user’s or project’s home space,
/ncrc/home[12]/$USER and /ncrc/proj/<project> respectively. If
the environment is to be shared by several users or groups, the environment can
in the /usw. Please open a help desk request to
establish a location under /usw.
Development
GPFS F5 should not be used for development. Development should be done in the user’s home space. This is especially true if using a source code management system (e.g., git).
Users should remember that GPFS F5 is not backed up. The user home area is backed up, with hourly and daily snapshots.
Known issues
The following is a list of issues we are currently investigating on the Gaea system. Please contact the RDHPCS support team for new updates.
Open issues
GPFS file system performance
We are investigating several GPFS (F5 and F6) performance issues. We have discovered that some slow read performance is likely tied to the GPFS file compression. We are working with ORNL and IBM to gather more information and for a resolution.
Data transfer performance
We are investigating an issue with transfers from Gaea to the GFDL archive system. This affects large transfers (files larger than 2TB), and the overall transfer performance. At this time, we believe transfers initiated using the Globus transfer app are not affected. We suggest users transferring large files to use Globus until a resolution is discovered.